How Ethereum execution clients see the P2P network: a peering deep dive


Every execution client connects to different peers, sees a different slice of the network, and churns through connections at wildly different rates. We queried Prometheus metrics and Elasticsearch container logs across our entire fleet to find out what each EC actually experiences at the P2P layer, and what it means for Ethereum's network health.

Why P2P peering matters
When people talk about Ethereum client diversity, the conversation usually centers around "what percentage of the network runs Geth?" But there's a deeper question that rarely gets asked: what does each client actually see?
Every execution client maintains its own set of P2P connections through the DevP2P protocol. These peers are the node's window into the Ethereum network. Through them, the node receives new transactions, propagates blocks, and participates in the state sync protocol. If your peers are slow, your node sees transactions late. If your peers all run the same client, a single bug could blind you.
We set out to answer a set of straightforward questions using our NDC2 bare-metal fleet in Vienna and GCP cloud instances (roughly 90 hosts running all 6 execution clients paired with all 6 consensus clients):
- How many peers does each EC maintain?
- Who are those peers? What clients do they run?
- How fast does each EC cycle through its peer set?
- Does the consensus client you pair with your EC influence its P2P behavior?
- What happens when DevP2P inbound ports are blocked?
- What does all of this mean for Ethereum's network health?
The fleet and the data sources
Our analysis combines two data sources: Prometheus metrics (7-day rolling averages via avg_over_time(...[7d:1h]) queries against our prometheus-cold datasource) and Elasticsearch container logs shipped by Filebeat from every EC container on the fleet. We've previously covered how these clients differ in sync speed and block building. This time, we're looking at how they differ in who they talk to.
Each EC exposes peer data differently. Some have rich Prometheus gauges; some log periodic peer reports; some give us almost nothing. Let's focus on what we actually found.
All peer counts and diversity percentages in this post are 7-day averages from the fleet unless noted otherwise. Individual snapshots can vary, as we'll see in the churn section.
Peer counts: from 25 to 130
The first and most basic question: how many peers does each EC maintain?
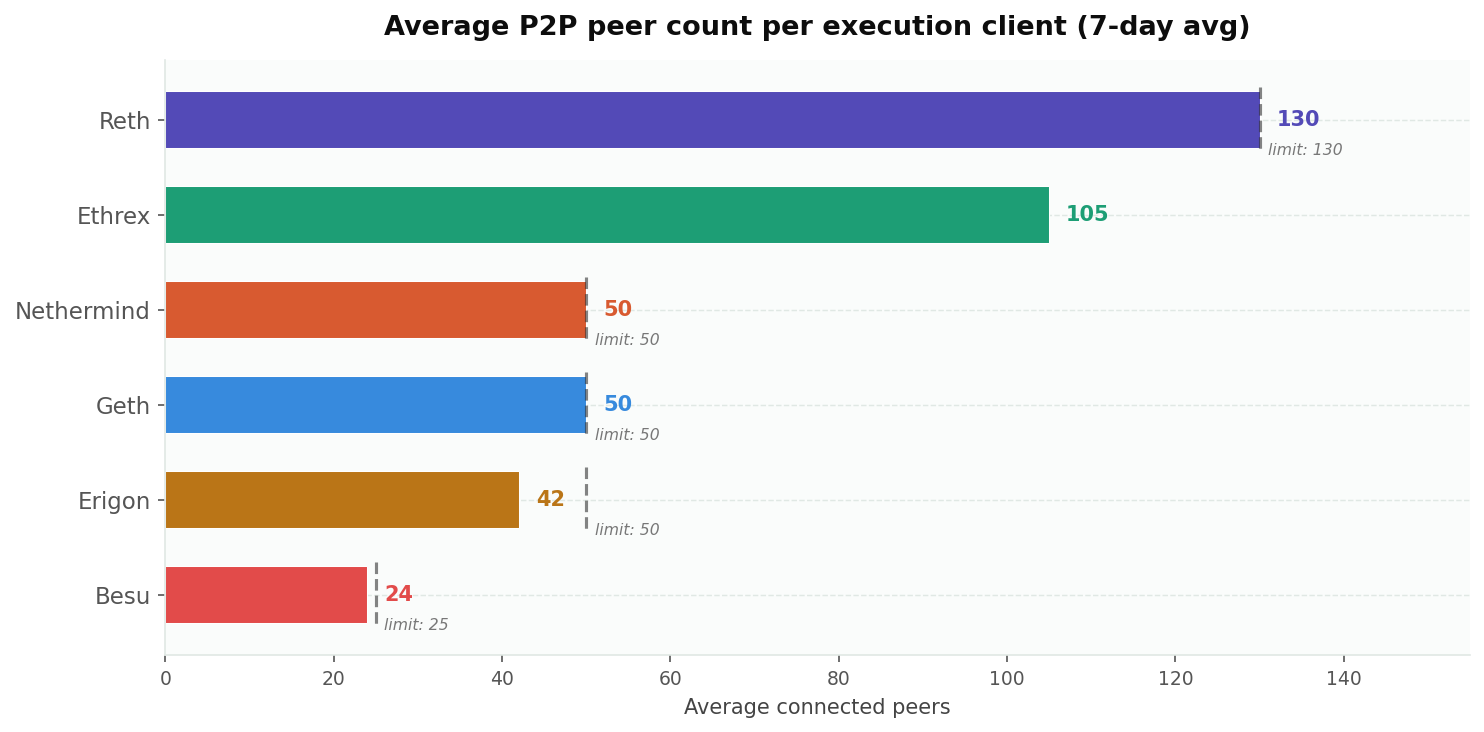
| EC | Avg peers | Configured limit | % of limit |
|---|---|---|---|
| Reth v2.1.0 | 130 | ~130 | 100% |
| Ethrex v10.0.0 | 105 | high (uncapped?) | — |
| Nethermind 1.36.2 | 50 | 50 | 100% |
| Geth v1.17.2 | 50 | ~50 | 99% |
| Erigon v3.3.10 | 42 | ~50 | 84% |
| Besu 26.4.0 | 24 | 25 | 95% |
The spread is striking: Reth maintains over 5x the connections Besu does. Every client except Erigon runs at or near its configured maximum, which means the peer limit is the binding constraint. Erigon is the outlier, consistently operating below its limit, and we'll see why when we look at its protocol behavior.
Besu's default --max-peers=25 is the lowest of any EC. If you're running Besu, consider raising this to at least 50. With only 25 peers, a single-client bug affecting your dominant peer type can severely degrade your view of the network.
What happens when DevP2P inbound ports are blocked?
Our GCP cloud instances ran Geth with the same configuration as our NDC2 bare-metal fleet, but with one critical difference: the GCP default firewall did not have port 30303 (DevP2P) opened for inbound traffic. This is a very common situation: most cloud providers (GCP, AWS, Azure) block all inbound traffic by default, and operators who don't explicitly open port 30303 TCP+UDP end up in exactly this state. The Geth process itself has no idea, it starts normally, makes outbound connections, and follows the chain.
The effect on peering is dramatic:
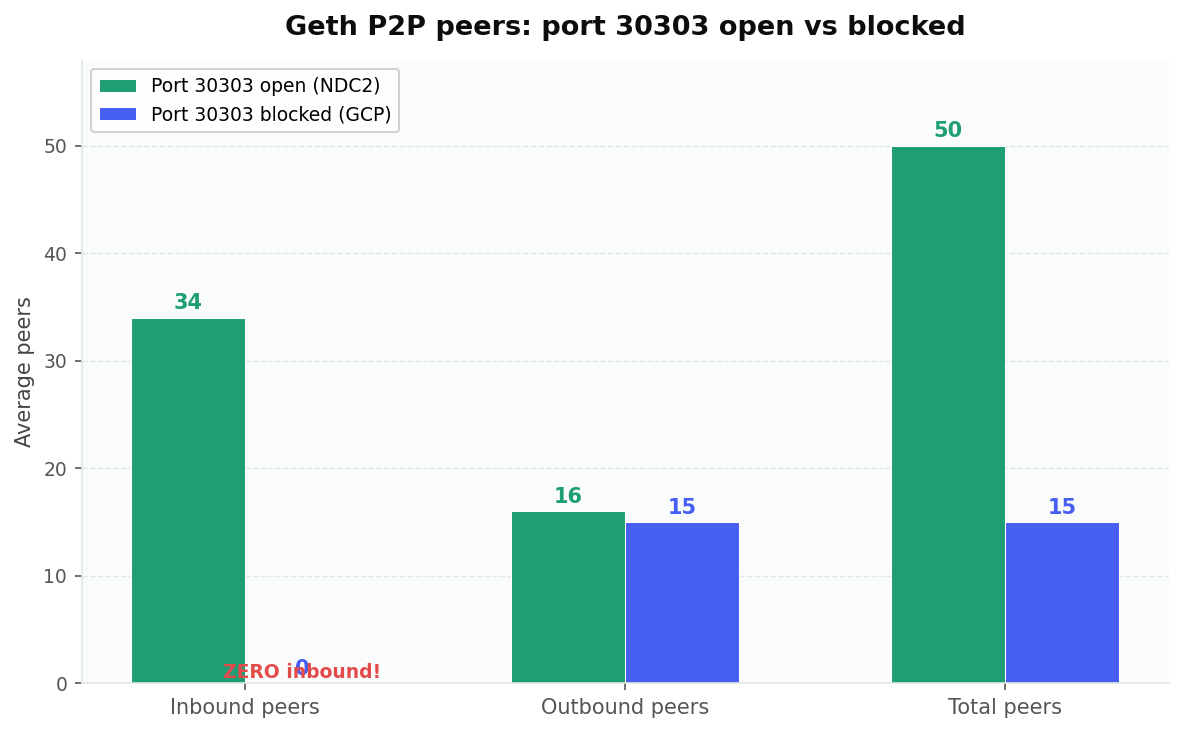
| Metric | Port 30303 open (NDC2) | Port 30303 blocked (GCP) |
|---|---|---|
| Total peers | 50 | 15 |
| Inbound peers | 34 | 0 |
| Outbound peers | 16 | 15 |
With inbound blocked, Geth receives zero incoming DevP2P connections. Its 15 peers are entirely self-initiated outbound connections. With the port open (NDC2), the same Geth configuration receives 34 additional inbound connections, reaching the full 50-peer capacity.
The outbound count is essentially identical (~15-16 both ways), confirming this isn't a Geth software or configuration difference. It's purely a network access issue. Geth initiates the same number of outbound connections regardless of whether it can receive inbound ones, but other nodes on the network simply can't reach it.
What makes this finding more nuanced is the consensus layer comparison. The CC-side libp2p peers are nearly identical: 158 on NDC2 vs 161 on GCP. The CCs use different ports and protocols (libp2p with QUIC and TCP), and those traverse NATs and firewalls without issues. This means an operator whose CC shows healthy peer counts has no obvious signal that their EC is running with 70% fewer connections than it could have. Everything looks fine on the consensus side while the execution layer is quietly degraded.
This is not a "cloud is worse than bare-metal" finding. Our GCP instances simply had port 30303 blocked by the default firewall, and we expect many cloud-hosted Ethereum nodes to be in the same situation. If you run a node on any cloud provider, check whether TCP and UDP port 30303 are open for inbound traffic. If not, your EC is operating with outbound-only connections, roughly 70% fewer peers, a thinner mempool view, and slower block/transaction propagation. Your CC peer count will look healthy and give no indication of the problem.
Who are the peers?
This is where things get interesting. Let's focus on the data we actually have: two ECs expose per-client peer breakdowns in Prometheus, and one logs it periodically.
Besu: 75% of peers are Reth
Besu exposes besu_peers_peer_count_by_client, giving us a full breakdown:
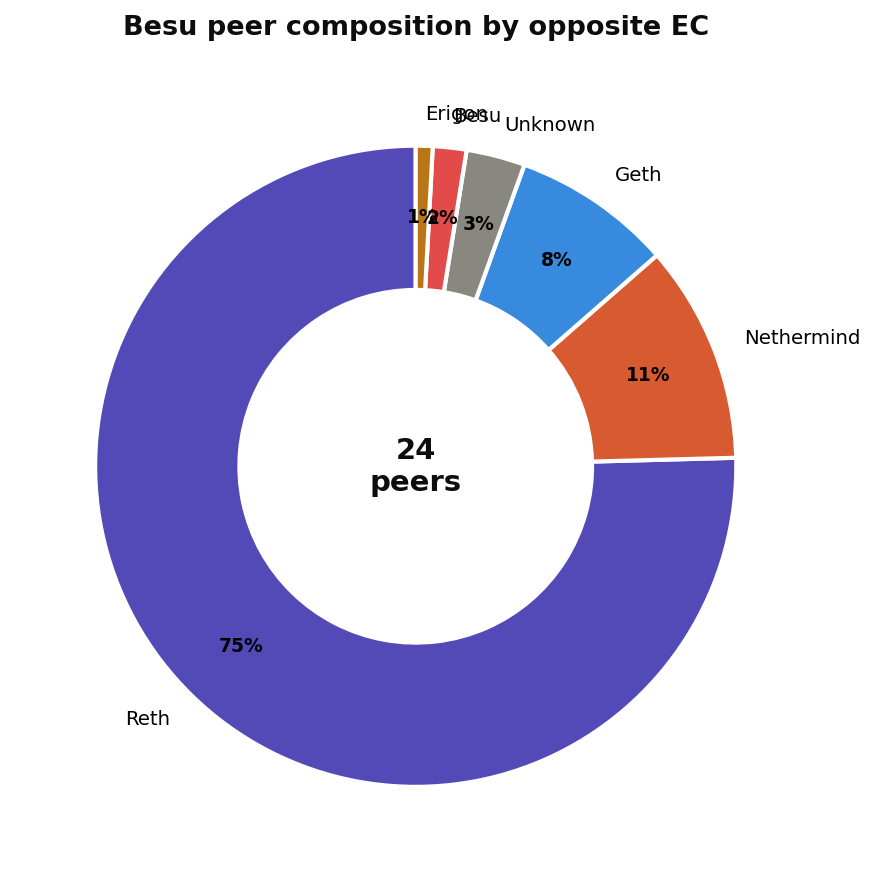
Out of Besu's 24 peers on average, 18 are Reth nodes. Only about 2 are Geth, and Erigon barely registers. This is a remarkably skewed distribution. With three quarters of its connections going to a single client, a Reth-specific networking bug would effectively isolate Besu nodes from most of their peers.
Ethrex: a broader but Geth-heavy view
Ethrex exposes ethrex_p2p_peer_clients with more granular labels:
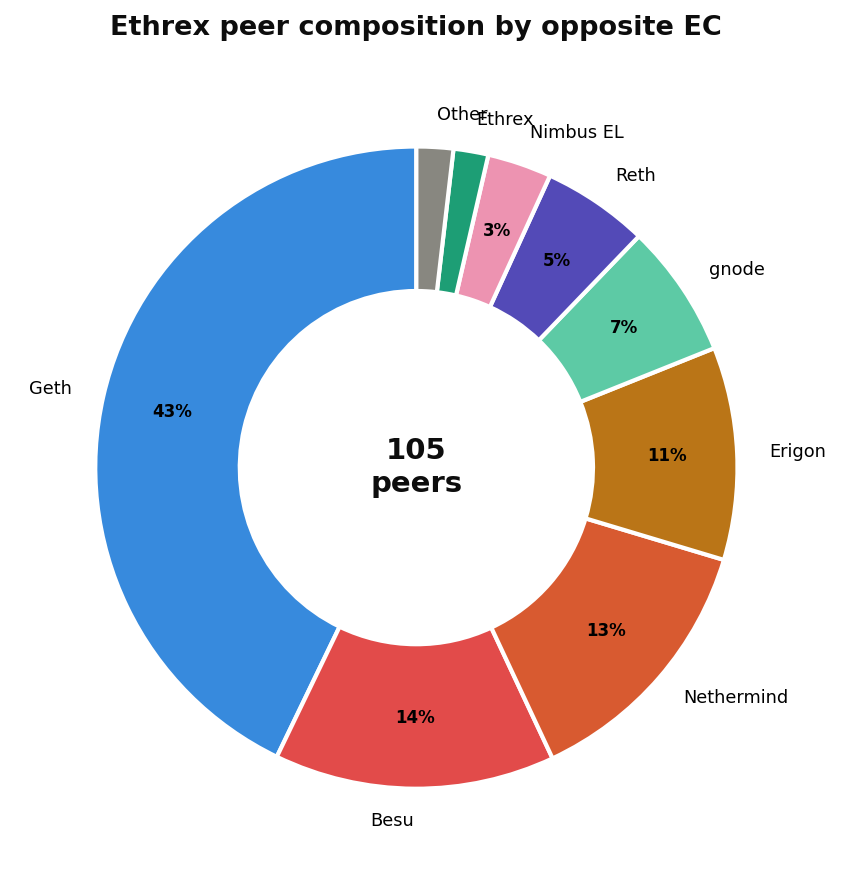
Ethrex sees a much more diverse peer set. Geth leads at 43%, but the remaining 57% is spread across five other clients. Notably, Ethrex picks up "exotic" peers that other clients don't: gnode (likely a Geth fork or private deployment), various Nimbus execution layer variants, and even mempool scrapers. Ethrex appears to be the most permissive in accepting connections from non-standard clients.
Nethermind: the most transparent
Nethermind doesn't expose per-client peer counts in Prometheus, but it does something even better: it logs a full diversity report every 5 minutes in its container output. These log lines are goldmines:
Peers: 49 | node diversity: Reth (37%), Geth (22%), Nethermind (20%), Unknown (14%), Erigon (4%), Besu (2%)
We pulled these from Elasticsearch across all 6 Nethermind instances (each paired with a different CC) and found something unexpected: the peer composition varies dramatically between instances in the same datacenter.
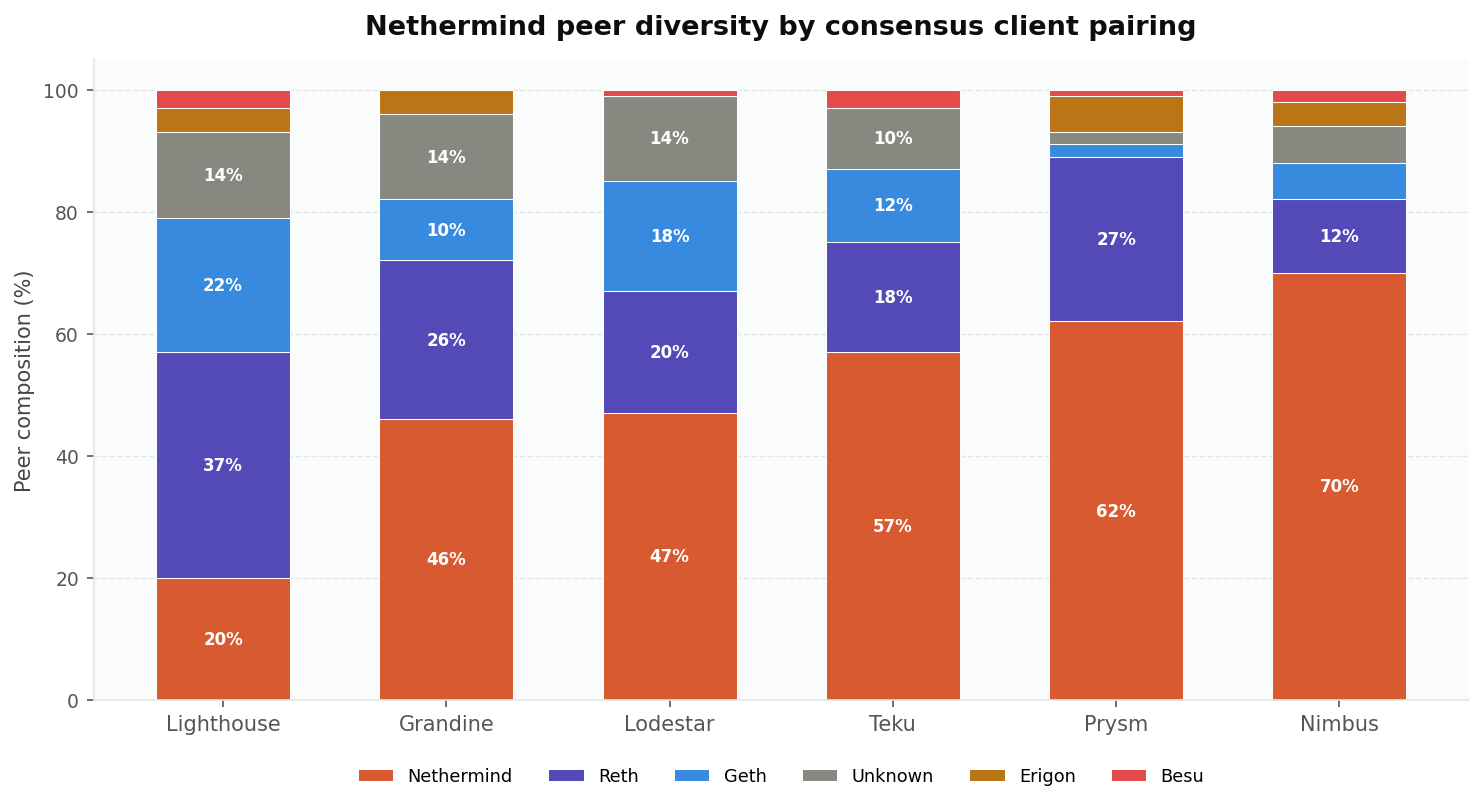
| CC pairing | Top peer | 2nd peer | 3rd peer |
|---|---|---|---|
| Lighthouse | Reth 37% | Geth 22% | Nethermind 20% |
| Grandine | Nethermind 46% | Reth 26% | Unknown 14% |
| Lodestar | Nethermind 47% | Reth 20% | Geth 18% |
| Teku | Nethermind 57% | Reth 18% | Geth 12% |
| Prysm | Nethermind 62% | Reth 27% | Erigon 6% |
| Nimbus | Nethermind 70% | Reth 12% | Unknown 6% |
The Nimbus-paired Nethermind instance sees 70% Nethermind peers, while the Lighthouse-paired one sees a relatively healthy mix with Reth leading at 37%. Same client, same datacenter, same network, vastly different peer views.
Does the consensus client affect EC peering?
This is one of the more subtle findings from the analysis. The short answer: the CC does not affect how many peers the EC gets, but it does affect which peers the EC keeps.
We checked peer counts per CC pairing across every EC on the fleet. The numbers are remarkably uniform:
| EC | Lowest CC pairing | Highest CC pairing | Spread |
|---|---|---|---|
| Geth | 49.3 (Lighthouse) | 49.6 (Teku) | 0.3 |
| Erigon | 41.8 (Teku) | 41.9 (Lighthouse) | 0.1 |
| Nethermind | 50.0 (Lighthouse) | 50.3 (Grandine) | 0.3 |
| Ethrex | 104.3 (Prysm) | 106.3 (Lighthouse) | 2.0 |
| Besu | 23.6 (Lighthouse) | 24.3 (Prysm) | 0.7 |
The CC pairing has essentially zero influence on peer count. Every Geth instance gets ~50 peers regardless of whether it runs with Lighthouse, Nimbus, or Teku. The same holds for every other EC.
But peer composition is a different story. The Nethermind diversity logs show a 50-percentage-point swing in Nethermind peer concentration (20% with Lighthouse vs 70% with Nimbus). The Besu Prometheus data tells a similar story at smaller scale: the Grandine-paired Besu gets 18.6 Reth peers while the Nimbus-paired one gets 17.8, with corresponding shifts in Nethermind and Geth counts.
The mechanism isn't direct. The CC doesn't participate in DevP2P at all. But the CC influences the EC's startup timing, engine API call patterns, CPU and memory pressure on the shared host, and the timing of when the EC first reaches out to the discovery network. Early peer bonding creates path dependency: the peers you discover first tend to persist, and the ones that persist shape which new peers you discover next through the Kademlia routing table. Different CCs create subtly different boot conditions, and those conditions cascade into measurably different peer equilibria.
This has a practical implication: two operators running the same EC and the same CC version might still see different peer compositions, simply because their nodes booted at different moments or under different system load. Peer diversity is partly a matter of luck.
Protocol adoption: eth68 vs eth69
Nethermind also logs the protocol version split among its peers, and Erigon reports its "GoodPeers" broken down by protocol:
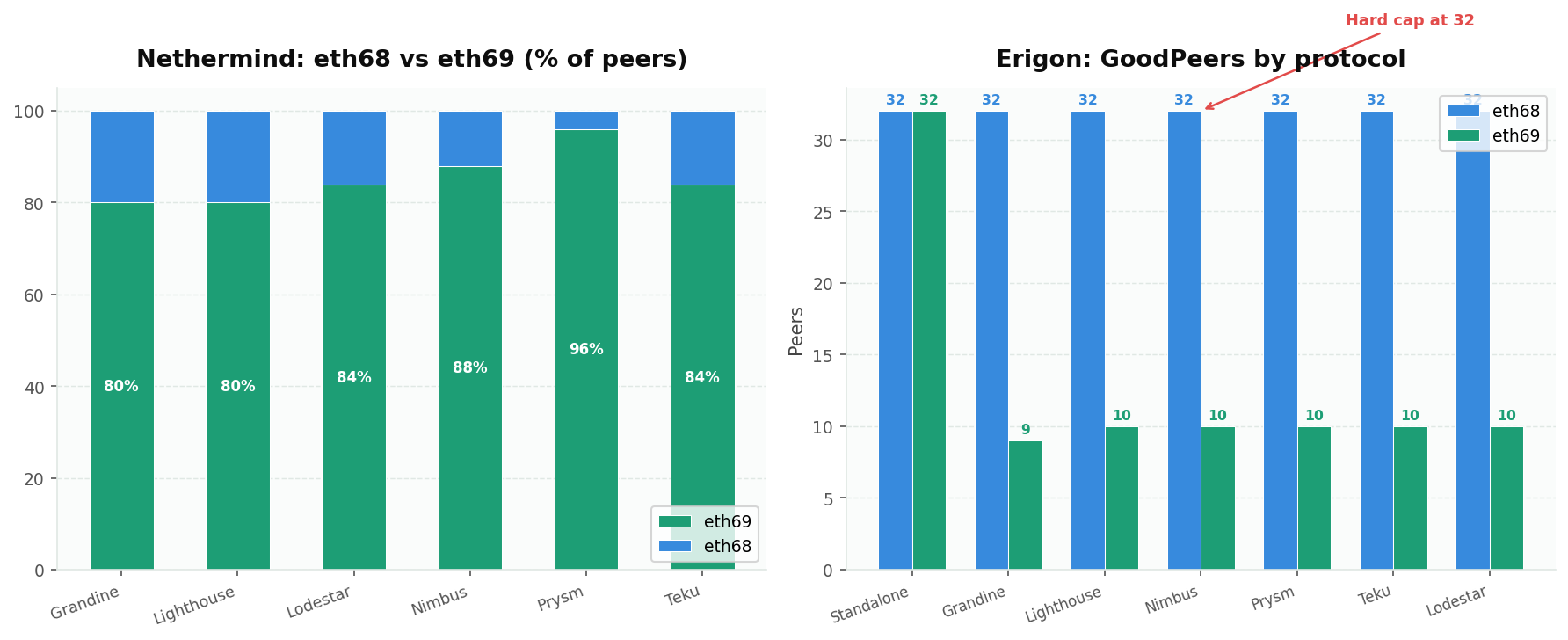
Nethermind's view: eth69 dominates at 80-96% depending on the instance. The Prysm-paired node sees the highest eth69 adoption (96%), while Grandine and Lighthouse-paired nodes see around 80%. This makes sense: Nethermind and Reth (its top peers) both adopted eth69 early.
Erigon's behavior is peculiar: every pairing shows exactly 32 eth68 GoodPeers. The eth69 count varies (9-32), but eth68 is always hard-capped at 32. The standalone Caplin instance gets 32+32=64 good peers, but CC-paired instances get only ~42. This hard cap on eth68 peers likely explains why Erigon consistently runs below its connection limit: it's artificially constraining its usable peer set by protocol version.
Erigon's eth68 hard cap at 32 means it's effectively running with a smaller usable peer set than its connection count suggests. If you're running Erigon and noticing slow block propagation, this protocol-level constraint could be a contributing factor.
Peer churn: who cycles and who holds
How fast does each EC rotate through its peer connections? This matters for network resilience: too little churn means stale, possibly slow peers accumulate; too much churn means constant overhead from handshakes and state negotiation.
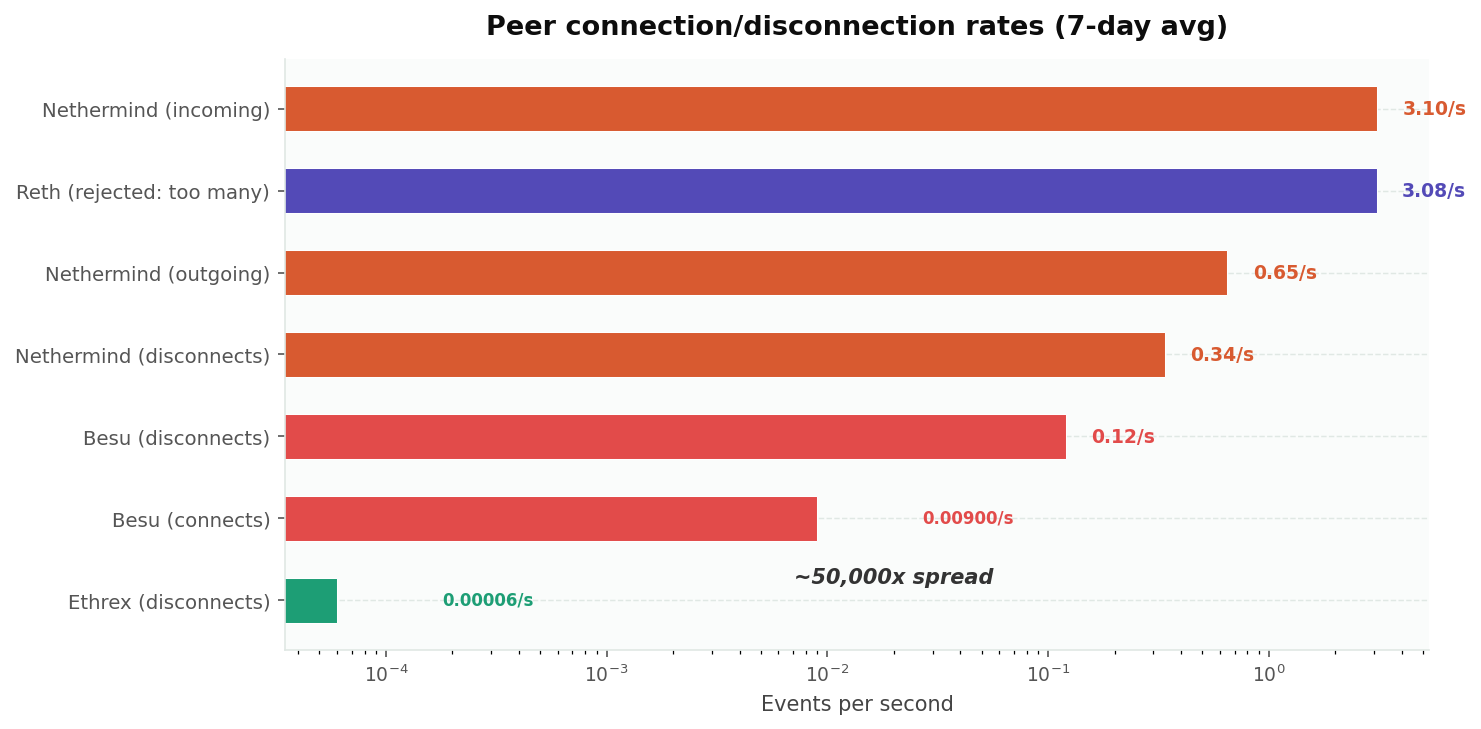
| EC | Key churn metric | Rate | Interpretation |
|---|---|---|---|
| Nethermind | Incoming connection attempts | 3.10/s | High inbound demand, rejecting most (at limit) |
| Reth | "Too many peers" rejections | 3.08/s | Constantly turning away new connections |
| Nethermind | Outgoing connections | 0.65/s | Moderate active peer seeking |
| Nethermind | Total disconnects | 0.34/s | Healthy rotation (~1,200/hour) |
| Besu | Disconnections | 0.12/s | Aggressive pruning despite few peers |
| Besu | New connections | 0.009/s | Very slow peer acquisition |
| Ethrex | Disconnections | 0.00006/s | Near zero, essentially static peer set |
The spread here is staggering: a factor of roughly 50,000x between the most and least churning clients.
Besu has the most aggressive peer rotation relative to its pool size: it disconnects at 14x the rate it connects. With only 25 slots, it's constantly cycling. Average peer sessions are very short.
Nethermind receives the most incoming connection attempts (3.1/s) but maintains a steady 50. Most incoming connections are rejected because the limit is reached, not because of quality issues.
Reth is the most sought-after peer on the network. It rejects ~3 connections per second, tracks 7,400 peers in its peer table (the largest DHT view of any EC on the fleet), and has 540 backed-off peers at any given time. Its 130 connected peers are stable and long-lived.
Ethrex has the most stable peering of any client we measured: essentially zero disconnection rate. Once it connects a peer, it keeps it indefinitely. This is a double-edged sword: stable peering means reliable gossip propagation, but no rotation means stale or slow peers are never pruned.
Every EC sees a different Ethereum
One of the most striking findings from this analysis is that no two execution clients see the same network. Even running on the same hardware in the same datacenter:
- Besu's 24 peers are 75% Reth. Its Ethereum is a Reth-dominated network.
- Ethrex's 105 peers are 43% Geth. Its Ethereum looks more like the "true" network composition.
- Nethermind's view changes depending on which CC it runs with. One instance sees 70% Nethermind peers; another sees 37% Reth.
- Erigon's protocol-level constraints give it a smaller effective peer set than its connection count suggests.
- Reth casts the widest net (7,400 tracked peers, 130 connected) but aggressively rejects newcomers.
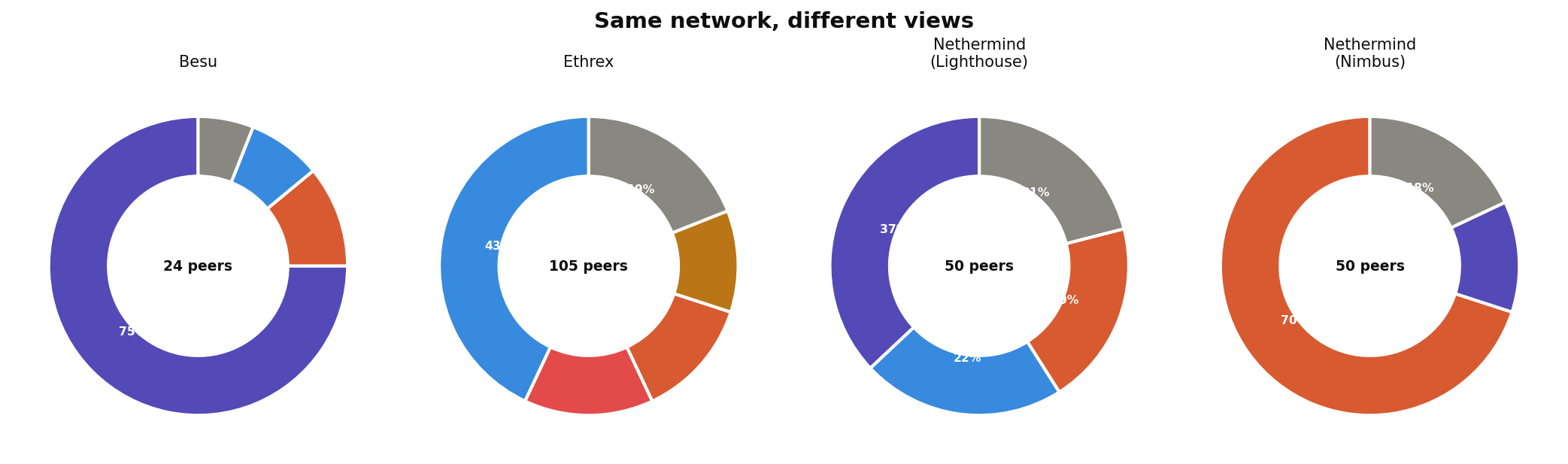
This per-client perspective gap is a form of network fragmentation that isn't visible in aggregate statistics. The overall network might be 55% Geth, but individual nodes don't experience that average. They experience their own biased sample.
What this means for Ethereum's network health
Client diversity at the EC layer is worse than it looks
Aggregate client diversity numbers (e.g., "Geth runs on 55% of nodes") describe the network as a whole, but individual nodes experience a much more concentrated version. When we hear that no single client exceeds 55% network share, it sounds like the network has a safety margin. But our data shows that at the individual node level, the picture is far less balanced.
A Besu node with 75% Reth peers doesn't live in a "55% Geth" network. It lives in a "75% Reth" network. If Reth pushes a release with a networking regression, that Besu node doesn't lose 20% of its peers (proportional to Reth's global share). It loses 75% of them. Similarly, a Nimbus-paired Nethermind node with 70% Nethermind peers is exposed to a Nethermind-specific issue at 3-4x the rate the aggregate numbers would suggest.
This matters in concrete scenarios:
Client-specific bugs during chain events. When a contentious or complex fork activates (as has happened multiple times in Ethereum's history), clients occasionally disagree on block validity for a short window. During these periods, nodes need diverse peers to hear both sides of the fork quickly. A Besu node whose 18 Reth peers all follow one fork branch would receive almost no blocks from the other branch for critical minutes.
Cascading failures from bad releases. If a popular client ships a broken release that causes resource exhaustion or crashes, nodes heavily peered with that client lose their connections simultaneously. On a healthy, diverse peer set, losing one client type drops you from 50 to 40 peers. On a Besu node with 75% Reth, it drops you from 24 to 6. Six peers is below the threshold where gossip propagation remains reliable.
Transaction propagation and MEV. Transactions are propagated through the EC peer mesh. If your peers are disproportionately one client, your node's mempool is shaped by that client's transaction acceptance logic, ordering behavior, and propagation timing. For validators, this can mean seeing fewer unique transactions and missing MEV opportunities. We've previously shown how EC choice affects block building output when paired with the same CC, and peer composition is one of the contributing factors: a node with a thin, homogeneous peer set simply sees fewer transactions to include.
Consensus finality during network partitions. If a network-level event (e.g., a BGP hijack, a cloud provider outage) takes out a large fraction of one client's nodes, the remaining network's ability to finalize depends on which clients can still communicate. Nodes with homogeneous peer sets are more likely to end up on the isolated side of a partition.
The fundamental issue is that DevP2P's discovery mechanism (Kademlia DHT with distance-based routing) is optimized for finding any peers, not diverse peers. Unlike the consensus layer's gossipsub protocol, which has explicit scoring and mesh-balancing mechanisms, the execution layer has no built-in incentive for client diversity. Peers are peers, regardless of what software they run. This means diversity at the node level is largely a side effect of the overall network composition and the node's own discovery path, and our data shows that path can lead to surprisingly concentrated outcomes.
Besu's low peer limit amplifies the problem
With a default of 25 peers and 75% of those being Reth, a Besu node has roughly 6 non-Reth connections to the Ethereum network. That's not just thin, it's fragile. At 6 connections, the loss of even 2-3 peers (through normal churn) can temporarily leave the node with only 3-4 diverse connections. Gossip propagation at that level is unreliable.
For comparison, Ethrex with 105 peers and 43% Geth still has 60 non-Geth peers even if every Geth node disappeared. That's still a functioning, well-connected node.
Ethrex's zero-churn peering needs attention
While stable connections improve gossip reliability in the short term, never pruning peers means degraded connections accumulate. If a peer goes slow but doesn't fully disconnect, Ethrex keeps it, potentially dragging down block and transaction propagation latency over time. Every other EC has some form of peer rotation that naturally filters out underperforming connections.
Blocked inbound ports are an invisible problem
Our GCP finding (zero inbound peers due to a default firewall that didn't have port 30303 opened) is likely representative of a large number of cloud-hosted Ethereum nodes. Operators who deploy to GCP, AWS, or Azure without explicitly opening DevP2P ports end up with only 15 outbound connections instead of 50, and their CC peer count gives no warning. A significant portion of the network may be operating with degraded EC connectivity without anyone noticing, which reduces the overall density of the gossip mesh and slows transaction propagation at scale.
The consensus layer shows what's possible
For comparison, the consensus layer's gossipsub mesh shows much better diversity. From our Lighthouse nodes' block gossip mesh:
| CC client | Mesh peers | Share |
|---|---|---|
| Prysm | 2.2 | 37% |
| Lighthouse | 1.6 | 27% |
| Teku | 1.1 | 19% |
| Nimbus | 0.5 | 9% |
| Lodestar | 0.4 | 6% |
No single client dominates more than 37%, and the gossipsub scoring system actively maintains diversity. The execution layer's DevP2P protocol has no equivalent mechanism. This is consistent with what we observed in our blob performance analysis, where data column gossip delay was uniform across all EC pairings, confirming that the CL's P2P layer operates largely independent of the EC underneath. If DevP2P were to adopt some form of diversity-aware peer scoring (even a soft preference for connecting to underrepresented clients), the per-node diversity picture could improve substantially without requiring any consensus-level changes.
Which EC failure would hurt Ethereum the most?
We can combine our peer dependency data with public network share estimates to model what would actually happen if a specific EC suffered a critical failure (a consensus bug, a bad release causing crashes, or a networking regression that takes all instances offline).
Current approximate EC network shares (from ethernodes.org and clientdiversity.org, April 2026):
| EC | Network share |
|---|---|
| Geth (incl. forks) | ~50% |
| Nethermind | ~21% |
| Reth | ~12% |
| Besu | ~11% |
| Erigon | ~5% |
| Ethrex | ~1% |
Before we model scenarios, an important nuance: an EC going offline does not automatically mean the validator goes offline. Professional staking operators (Coinbase, Lido's curated set, institutional stakers) typically run multiple ECs with failover at the validator client or signer level. If Geth crashes, their validator client can switch to a Nethermind or Besu backup within seconds. For these operators, an EC failure causes a brief blip, not a prolonged outage.
Solo stakers, home stakers, and smaller operators are a different story. Most run a single EC paired with a single CC. For them, an EC failure means their validator goes offline until they manually intervene: restart the client, wait for a patch, or migrate to a different EC entirely (which means syncing from scratch, a process that can take anywhere from 1.5 hours to 8+ days depending on the client).
The real-world impact of an EC failure therefore depends on the mix of professional vs solo operators running that client. The scenarios below model the P2P cascading effects, which hit everyone regardless of their failover setup.
Scenario 1: Geth fails. This is the most impactful scenario by raw numbers. Roughly half of all execution client instances go offline. On our fleet, Ethrex would lose 43% of its peers in one stroke. Nethermind instances peered heavily with Geth (the Lighthouse-paired one sees 22% Geth) lose a significant chunk too. For validators, the impact is split: professional operators with EC failover switch to their backup within seconds and keep attesting. Solo stakers running only Geth go dark until the issue is resolved. Whether finality breaks depends on how many of Geth's ~50% share consists of solo stakers without failover. If even a third of them can't switch quickly, that's ~17% of validators going offline, which combined with normal churn could push the network close to the 1/3 offline threshold where finality stalls. Even short of that threshold, the gossip mesh takes a massive hit: surviving ECs lose a large fraction of their peers simultaneously, transaction propagation slows across the board, and block proposals from surviving validators may include fewer transactions because the mempool is suddenly thinner.
Scenario 2: Reth fails. At ~12% network share, a Reth failure seems manageable at first glance. But our data reveals a cascading dependency that makes this worse than the headline number suggests. Besu nodes on the fleet derive 75% of their peers from Reth. If Reth goes down, the average Besu node drops from 24 peers to 6. At 6 peers, gossip propagation becomes unreliable: blocks arrive late, transactions get missed, and the node may struggle to stay in sync. In effect, a Reth failure doesn't just remove 12% of the network's EC instances. It functionally degrades another 11% (Besu's share), potentially pushing Besu nodes below the peer threshold needed for reliable chain following. Besu validators don't go offline in the strict sense, their EC is still running, but they start missing attestations and producing delayed block proposals because their view of the chain is degraded. That turns a 12% EC outage into something closer to a 20-23% effective network degradation, well beyond what the simple market share numbers would predict.
Scenario 3: Nethermind fails. At ~21% share, a Nethermind failure is the most concerning for the professional staking segment, since Nethermind has been the primary beneficiary of the "move away from Geth" push (Coinbase, stakefish, and others have publicly migrated large validator sets to Nethermind). These operators likely have failover, but the sheer scale of simultaneous failover events could create its own pressure: backup ECs suddenly handling double the engine API load, discovery networks flooded with reconnection attempts, and a temporary peer diversity shock as the second-largest client disappears from the gossip mesh. The Nethermind-to-Nethermind peering concentration we observed (up to 70% on some instances) means that even surviving Nethermind nodes, those that haven't crashed but are peered with ones that did, lose most of their connections and need to re-discover peers.
The counterintuitive finding: By raw network share, Geth is the obvious answer for maximum damage. But Reth's failure is disproportionately dangerous relative to its 12% market share because of the peer dependency it has created with Besu. A 12% client taking down its own nodes plus functionally crippling an 11% client through peer starvation is a 2x amplification factor that no aggregate diversity statistic captures.
This peer dependency amplification is invisible in the standard client diversity charts. The usual framing ("no client above 33%") assumes that each client's failure is contained to its own nodes. Our data shows that's not the case at the P2P layer. Client failures cascade through the peer graph, and the pattern of those cascades depends on the specific, measurable peer composition that each client maintains. This is exactly the kind of second-order effect that requires fleet-level observability to detect.
This is just the surface
This analysis is a short snapshot of one aspect of our fleet data. At StereumLabs, we continuously collect Prometheus metrics and container logs across all 6 consensus clients and all 6 execution clients, in every pairing, on both bare-metal (NDC2 Vienna) and cloud (GCP) infrastructure.
We use this data for version comparison reports (like our Teku cross-version analysis and Prysm resource comparison), hardfork impact analysis, security audits, and deep dives like this one. The P2P peering layer alone has months of historical data waiting to be mined: how does peer diversity change over time? Do software updates shift the composition? What happens during hardfork activations? How do different geographic locations affect peering patterns?
The dashboards are there, the data is there, and there is much more to find. If you're a researcher, an Ethereum client team, or an infrastructure operator and you want to dig deeper, get in touch. You can also watch our EthCC[9] talk for a broader overview of how we use AI-powered observability across the Ethereum staking stack.
- Prometheus metrics: 7-day rolling averages using
avg_over_time(...[7d:1h])instant queries against ourprometheus-colddatasource (UIDaez9ck4wz05q8e, Grafana Org 6). - Elasticsearch logs: Queried via Grafana's
_msearchproxy against Filebeat container log indices. Filtered bycontainer.image.nameper EC version. - Fleet: NDC2 bare-metal (Vienna) for all 6 ECs paired with all 6 CCs. GCP cloud instances (europe-west3) for Geth paired with all 6 CCs (supernode configuration, default firewall with port 30303 not opened for inbound).
- EC versions: Besu 26.4.0, Erigon v3.3.10, Ethrex v10.0.0, Geth v1.17.2, Nethermind 1.36.2, Reth v2.1.0.
- CC versions: Lighthouse v8.1.3, Lodestar v1.42.0, Nimbus multiarch-v26.3.1, Teku 26.4.0, Grandine 2.0.4, Prysm v7.1.3.
- Date of snapshot: April 29, 2026.